
Нейронные сети и вирусы
Могут ли хакеры обратить во зло искусственный интеллект
Образ хакера в современных медиа — это образ мага, чудотворца, у которого роль заклятий играют скрипты, вирусы и многое другое. Хакеры в одиночку, практически с телефона, способны взломать самую совершенную систему безопасности, пробиться через любой файерволл. Хакеры-преступники в этом контексте представляются злыми волшебниками, использующими современные инструменты во зло. Один из таких инструментов — это, разумеется, искусственный интеллект.
Искусственный интеллект — это зонтичный термин, включающий в себя довольно много разных инструментов, связанных с нейросетями, большими данными и машинным обучением. Чаще всего он используется для обозначения нейросети, натренированной на решение какой-либо, чаще всего интерпретационной, задачи: распознавание речи, изображений, перевод текстов с контекстом с языка на язык и так далее.
Обычная нейросеть — это в первом приближении сложно устроенная математическая функция f(x, a), которая зависит от набора аргументов x и некоторого набора параметров a. Она получает на вход данные определенного формата и выдает результат.
Создание самой простой нейросети выглядит так. Сначала определяется задача, потом выбирается тип нейросети. Дальше находится массив размеченных данных. На этих данных нейросеть обучается, то есть в автоматическом режиме подбираются такие значения параметров a, чтобы на размеченной выборке функция принимала нужные значения.
Наконец, сеть тестируется, и после этого, в принципе, она готова к работе — если на всех предыдущих этапах ничего не сломалось, если выборка была хорошей, если удалось угадать правильную архитектуру сети и так далее.
Судя по всему, узкая специализация — это математическое свойство, не зависящее от физической реализации этого инструмента. Это означает, что если вам требуется решить задачу, пусть и близкую, но отличную от той, которую решает имеющаяся нейросеть, то вам придется заново разрабатывать новую.
Наконец, нейросеть не программируется в привычном понимании этого слова. Это означает, что проверка теоретической корректности полученного результата (как проверка алгоритма в программе) требует создания новых методов, инструментов. Иными словами, вопрос безопасности работы — а под безопасностью мы понимаем отсутствие сбоев — это нерешенная задача, для которой еще предстоит создать подходящие инструменты.
Современные хакеры имеют мало общего с тем образом профессионалов-одиночек, который представлен в телевизионных сериалах. Хакеры, занимающиеся противоправными действиями, в массе своей входят в организованные преступные группировки, зачастую объединяющие большое число программистов сравнительно невысокого уровня.
Их основная цель, как и любой ОПГ, — извлечение прибыли с минимальными расходами и рисками. Этим определяются основные направления работы киберпреступников: львиная доля совершаемых ими преступлений завязана на воровстве личных данных пользователей, мошенничестве и вымогательстве.
Соответственно, можно выделить пять основных типов киберугроз.
Больше половины всех киберугроз — это заражение компьютеров вредоносным программным обеспечением. Помимо привычных всем вирусов на сайтах, хакеры давно используют более любопытные технологии — например, встраивают вредоносный код в open-source проекты или заражают серверы для автоматического обновления ПО.
В последнем случае через такую систему были заражены десятки (а возможно, и сотни) тысяч компьютеров по всему миру.
Еще один тип — индивидуальные мошеннические атаки. Они подразумевают прямой контакт с пользователем с целью убедить человека отдать данные или добровольно установить то или иное приложение, содержащее вредоносный код. В подобных атаках часто участвуют живые люди, которые могут притворяться службой поддержки, сотрудниками банка и так далее.
Такие атаки подразумевают чаще всего прямое воровство денег. Иногда следствием атаки становится заражение вирусом, который кодирует данные и требует перевода денег для разблокировки (это виртуальная форма вымогательства).
Классический взлом систем с использованием программ, скриптов и так далее. На этот вид преступлений приходится чуть меньше 17 процентов от всех киберугроз.
Часто это часть глобальной схемы — например, заражение серверов вредоносными программами. Одна из основных целей хакерских атак (помимо традиционных государственных институтов) — криптобиржи и прочие площадки, связанные с криптовалютой.
По-прежнему пользуются популярностью атаки на сайты. В основном речь идет про онлайн-магазины и прочие площадки, аккумулирующие личную информацию своих пользователей. Эти данные либо просто похищаются, либо используется схема с вымогательством.
Наконец, последний тип — это не устаревающие DDos-атаки. В июле 2019 года им исполнилось ровно 20 лет. Основная идея здесь состоит в создании сети ботов — компьютеров, готовых по команде посылать запросы на заданный сервер, перегружая его.
К 2019 году искусственные нейронные сети стали чем-то большим, чем просто забавная технология, о которой слышали только гики. Да, среди обычных людей мало кто понимает что из себя представляют нейросети и как они работают, но проверить действие подобных систем на практике может каждый – и для этого не нужно становиться сотрудником Google или Facebook. Сегодня в Интернете существуют десятки бесплатных проектов, иллюстрирующих те или иные возможности современных ИНС, о самых интересных из них мы и поговорим.
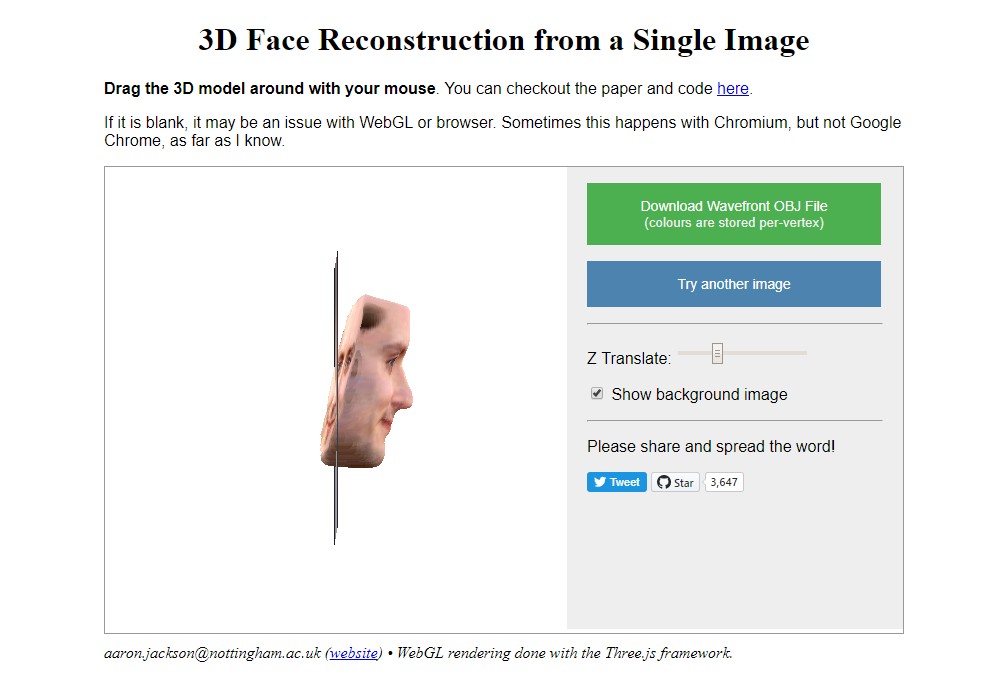
На этом сервисе вы сможете вдохнуть новую жизнь в свои старые фотографии, сделав их объемными. Весь процесс занимает меньше минуты, необходимо загрузить изображение и через несколько секунд получить 3D-модель, которую можно покрутить и рассмотреть во всех деталях. Впрочем, есть два нюанса — во-первых, фотография, должна быть портретной (для лучшего понимания требований на главной странице сайта представлены наиболее удачные образцы снимков, которые ранее загружали другие пользователи; во-вторых, детализация получаемой модельки зачастую оставляет желать лучшего, особенно, если фотография в низком разрешении. Однако авторы разрешают не только ознакомиться с результатом в окне браузера, но и скачать получившийся файл в формате obj к себе на компьютер, чтобы затем самостоятельно его доработать.
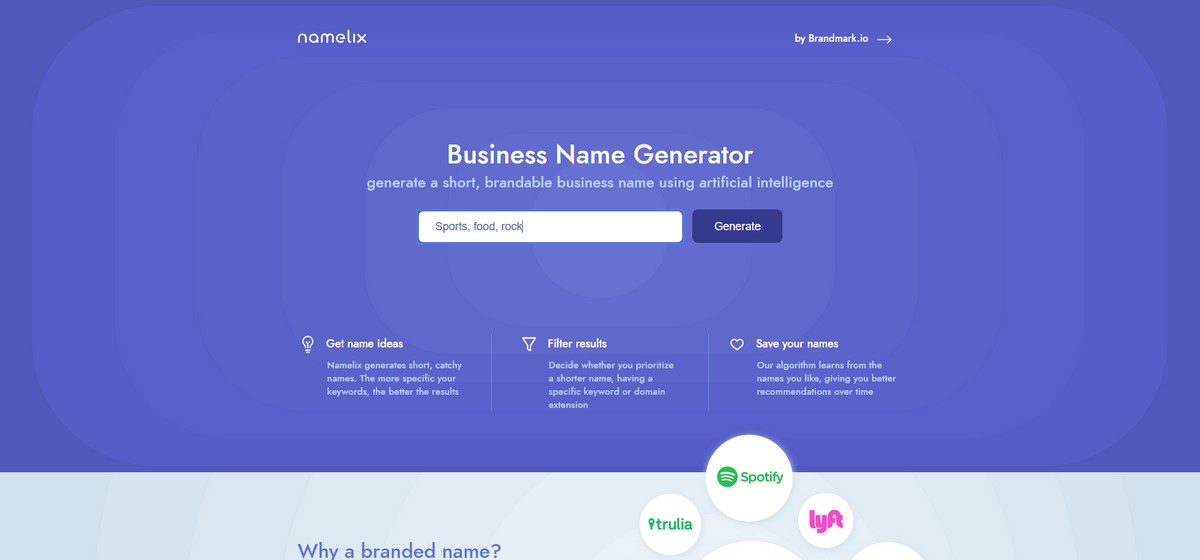
Придумали крутую идею для стартапа, но не можете определиться с именем для будущей компании? Достаточно вбить несколько ключевых слов, задать длину названия в символах и готово! В общем, больше не нужно искать на фрилансе людей, которые будут решать такой личный вопрос, как наименование дела всей вашей жизни.

Пересмотрели все интересные вам фильмы, прочли все достойные книги и не знаете чем занять вечер? Система рекомендаций от специалиста по искусственному интеллекту Марека Грибни расскажет как увлекательно и с пользой провести свободное время. Для корректной работы сервиса вас сперва попросят указать ваши любимые произведения в кинематографе, литературе, музыке или живописи.
Google специально для поклонников современного (и не только) искусства запустила проект Google Arts & Culture, в котором можно подобрать произведения по вашему вкусу как от малоизвестных, так и от малоизвестных авторов. Большая часть контента здесь на английском, но если вы не дружите с языками, можно воспользоваться встроенным переводчиком.
Японская студия Qosmo разработала очень необычную нейросеть Imaginary Soundscape, которая воспроизводит звук, соответствующий тому или иному изображению. В качестве источника информации вы можете указать ссылку на любую картинку в Интернете, загрузить свой файл либо выбрать случайную локацию на Google Maps.

Если вы пробовали использовать рукописный ввод на своем смартфоне, эта нейросеть покажется вам до боли знакомой: она превращает любые каракули в аккуратные 2D-рисунки.

Thispersondoesnotexist – это один самых известных AI-проектов. Нейросеть, созданная сотрудником Uber Филиппом Ваном, выдает случайное изображение несуществующего человека при каждом обновлении страницы.

Тот же автор разработал аналогичный сайт, генерирующий изображения несуществующих котов.
Часто ли вам приходится тратить драгоценное время на удаление бэкграунда с фотографий? Даже если регулярно такой необходимости не возникает, следует на всякий случай знать о возможности быстрого удаления фона с помощью удобного онлайн-инструмента.

Компания ‘Яндекс’, известная своей любовью к запуску необычных русскоязычных сервисов, имеет в своем портфолио сайт, где искусственный интеллект составляет рандомные стихотворения из заголовков новостей и поисковых запросов.

Colorize – это также российская нейросеть, возвращающая цвета старым черно-белым снимкам. В бесплатной версии доступно 50 фотографий, если вам нужно больше, можете приобрести платный аккаунт с лимитом в десять тысяч изображений.
Лет 10-15 назад камеры мобильных устройств не отличались высоким разрешением, и слабый сенсор в телефоне никак не мог справиться с детализированной картиной окружающего мира. Теперь же, если вы захотите повысить разрешение своих старых фотографий, это можно сделать на сервисах вроде Bigjpg и Let’s Enhance, которые позволяют увеличить размер изображения без потери в качестве.

Благодаря высоким технологиям, сегодня у вас есть возможность озвучить любую фразу голосом самых известных в мире людей. Все просто: пишите текст и выбираете человека (среди последних — Дональд Трамп, Тейлор Свифт, Марк Цукерберг, Канье Уэст, Морган Фриман, Сэмюель Л Джексон и другие).
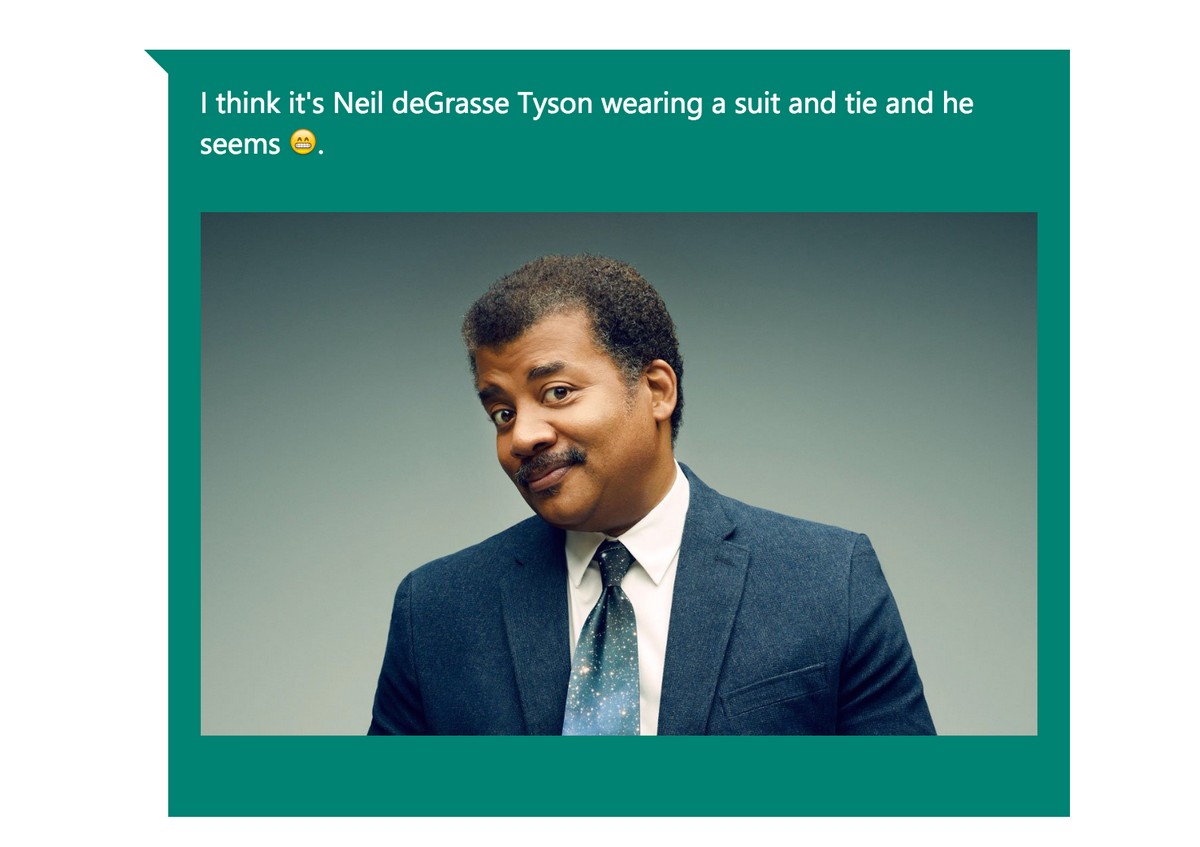
Казалось бы, искусственный интеллект должен быть способен без труда описать любую, даже самую сложную картинку. Но это вовсе не так, обучить ИИ распознавать отдельные образы действительно относительно просто, а вот заставить компьютер понимать общую картину происходящего на изображении, очень сложная задача. У Microsoft получилось с ней справиться, и ее CaptionBot без труда скажет, что вы ему показываете.
Напоследок расскажем о целой пачке нейросетей от Google, первая из них – Infinite Drum Machine. Открыв страницу приложения, вы увидите своеобразную карту, на которой находятся самые разнообразные звуки. С помощью круглых манипуляторов можно изменять сочетание элементов, если получившийся набор покажется вам бессмысленным, нажмите кнопку Play в нижней части экрана и звуковая картина сложится сама собой.
Если предыдущий сервис может оказаться полезным для, например, диджеев или обычных музыкантов, то польза от управления голосами десятков тысяч певчих птиц довольно сомнительна. Кстати, коллекция звуков для Bird Sounds собиралась орнитологами со всего мира на протяжении нескольких десятилетий.
В A. I. Duet пользователю предлагается сыграть какую-нибудь мелодию на пианино, а искусственный интеллект попробует самостоятельно закончить композицию, подобрав наиболее логичное и гармоничное продолжение.
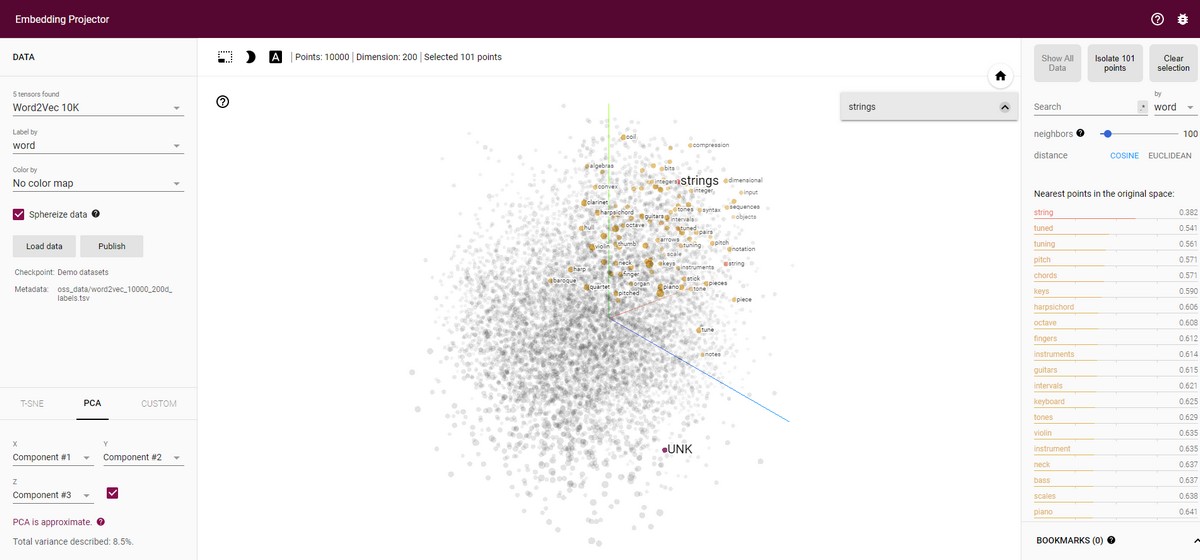
Проект Visualizing High-Dimensional Space (“Визуализация многомерного пространства”) создавался для того, чтобы объяснить простым людям и начинающим разработчикам, как работают нейросети. Когда ИИ, оперируя большими базами данных, получает информацию (например, вашу фотографию, введенную фразу или только что нарисованное изображение), он сравнивает входящие данные с теми, что у него уже есть. VHDS наглядно демонстрирует корреляцию одного лишь выбранного вами слова с миллионами аналогичных понятий.

Рубрика: Информационные технологии
Дата публикации: 28.11.2017 2017-11-28
Статья просмотрена: 273 раза
В этой статье будет рассмотрен метод обучения глубокой нейронной сети для автоматической генерации сигнатур вирусов, с целью дальнейшего предотвращения заражения информационных систем. Метод использует сеть глубоких убеждений, реализованную с глубоким стеком шумопонижающих автокодеровщиков, генерирующих инвариантное поведение вредоносного ПО. В отличие от обычных методов подписи, которые не могут обнаружить большинство новых вариантов, существующих вредоносных программ, подписи, сгенерированные по методу глубокого обучения, позволяют получить точную классификацию новых вариантов вирусов. Благодаря использованию набора данных, содержащего сотни вариантов для нескольких основных семейств вирусов, с помощью данного метода можно достичь почти 98 % точности в классификации вирусных сигнатур (характерных признаков вирусов).
Ключевые слова: глубокая нейронная сеть, сигнатура вируса, песочница, вредоносное ПО, сетевой трафик
Введение
Несмотря на почти экспоненциальный рост числа новых вирусов (например, по данным Panda Security в 2016 году в день появлялось почти 160 000 вредоносных программ), методы защиты от этих угроз остались неизменными. Большинство антивирусов обнаруживают вредоносное ПО, анализируют его и вручную создают специальную подпись, которую выпускают, как обновление. Ручной анализ, как правило, занимает много времени. Вредоносное ПО остается незамеченным и продолжает заражать новые компьютеры. Так же при обнаружении вирусов вносятся лишь минимальные изменения в код, так что новый вариант вируса практически невозможно обнаружить быстро.
Для автоматизации поиска вредоносного ПО было предложено несколько методов генерации сигнатур, такие как подписи на основе конкретных уязвимостей, полезная нагрузка, приманки и т. д. Основной недостаток этих методов в том, что они нацелены на конкретные аспекты вредоносного ПО, что позволяет разработчикам вирусов создавать новые варианты, изменяя малые части кода.
В этой статье будет представлен новый метод подписи, который не зависит от конкретных аспектов вирусов и тем самым инвариантен ко многим модификациям вирусного кода. Метод опирается на обучение глубокой сети убеждений или, по-другому, глубокой неконтролируемой нейронной сети, которая инвариантна в представление общего поведения вредоносного ПО.
В следующем разделе будут рассмотрены несколько предыдущих подходов для автоматической генерации сигнатур. В разделе 3 будет описан метод глубокого обучения. В четвертой главе будут представлены заключительные замечания.
Обзор подходов автоматической генерации сигнатур
Очень сложно успешно генерировать подписи, которые могут использоваться для предотвращения новых атак. Обычные методы без автоматизации неэффективны против вредоносных программ. Поэтому было предложено несколько подходов для улучшения процесса генерации подписи. Кратко рассмотрим несколько из них.
В основном все эти методы строятся на анализе трафика [1] (при условии, что трафик существенно не меняется для каждого варианта вредоносного ПО). Подпись фиксирует источник и соединение, предпринятое извне сети (входящие соединение). Внешний источник считается вредоносным, если он сделала более чем определенное количество попыток подключиться к IP-адресу сети. Подпись выбирает наиболее часто повторяющуюся последовательность байтов из трафика этого источника и использует ее в качестве своей подписи. Однако вредоносная программа может уклоняться от обнаружения, изменяя свою наиболее часто используемую последовательность байтов.
Аналогичный подход для генерации подписи на основе сетевого трафика представляют ячеистые сенсорные сети, которые используют наибольшие общие подстроки для генерации сигнатур и измерения сходства в пакетных нагрузках. Датчик контролирует поток информации в сети и пытается обнаружить вредоносные атаки с использованием аномалий. Пакеты, связанные с атаками и нулевым днем (вирусы, для которых еще не разработаны защитные механизмы) отличаются от обычного сетевого трафика. [3]
Другой метод Amd генерирует семантические коды и указывает условия для совпадения между шаблонами и проверяемыми программами. Полиграф генерирует подписи, которые в свою очередь используют подстрочные подписи, для расширения возможностей обнаружения вредоносных программ.
Большинство вирусов представляют из себя многомодульные программы, содержащие большое число подмодулей и поэтому статистического анализа недостаточно для их точной классификации. Авто-знак [3] генерирует список подписей для вредоносного ПО путем разделения его исполняемого файла на сегменты равного размера. Для каждого сегмента создается подпись. Список подписей в следствии оценивается. Этот метод более устойчив к небольшим изменениям, но вредоносное ПО может уклоняться от этого метода путем шифрования исполняемого файла. Таким образом оно уклоняется от любого метода, который сравнивает исполняемые файлы и подпись.
Предлагаемый метод генерации подписей
В этом разделе представлен новый подход к поколению подписей. Главный вопрос, на который мы попытаемся ответить: возможно ли сгенерировать подпись для программы, чье поведение является инвариантным к малым масштабам изменений.
В 2014 году студенты из университета штата Пенсильвания провели эксперимент, который заключался в следующем.
С помощью глубоких автокодеровщиков было обработано больше 10000 рандомных изображений, взятых из Интернета. Для каждого из них был создан короткий двоичный код. На основе сравнения этих кодов было выяснено, что, например, изображения слонов имеют одинаковые участки кода.
Предлагаемый метод состоит из следующих этапов:
- Неконтролируемый этап обучения. На этом этапе учитывается набор вредоносных программ;
- , Запуск каждой программы в песочнице для генерации текстового файла, содержащего поведение программы.
- Анализ текстового файла песочницы и преобразование его в двоичную битовую строку
- Передача строк в нейронную сеть.
- Многоуровневое обучение глубокой сети убеждений с использованием глубоких шумопонижающих автокодеров. Обучение полностью неконтролируемо, и сеть не знает метки каждого образца.
Сеть имеет восемь уровней, каждый из которых содержит 30 нейронов. Таким образом, полученная в результате глубокая сеть в основном генерирует подпись, содержащую 30 чисел с плавающей запятой для каждого программа запускается в песочнице. Песочница — это особая среда, которая позволяет вести журнал поведения программ (например, вызов функций API, их параметры и файлы созданные или удаленные). [5] Результаты сохраняются в файле (обычно текстовом). На рисунке 1 представлен фрагмент журнала, записанный в виде песочницы.

Рис. 1. Фрагмент журнала, записанный в виде песочницы
Мы используем большой набор данных, содержащий несколько основных категорий вредоносных программ и нескольких сотен вариантов подписей для каждой программы. Обученная сеть генерирует подпись для каждого образца вредоносного ПО. Качество и способность представления этих генерируемых подписей изучается путем запуска на них нескольких контролируемых методов классификации. Результаты показывают, что глубокая нейронная сеть достигает 98 % точности классификации при проверке данных, что свидетельствует о высокой степени обучаемости сети.
Самый простой способ преобразования созданной песочницы из текстового файла в строку фиксированного размера — использовать один из общих методов обработки естественного языка. Простейший из этих методов — однограммовая (1-граммовая) экстракция или извлечение. Например, учитывая набор данных для образцов текста, сначала в тексте находится 5000 наиболее частых слова (эти слова будет содержать словарь), а затем для каждого тестового примера проверяется, какие из этих 5000 слов присутствуют в строке. Таким образом, каждый образец текста представлен как бит-строка размером в 5000. В отличие от текста на языке файла, файлы песочницы содержат разнообразную информацию и требуют несколько этапов предварительной обработки для извлечения полезного содержимого (например, строка после тега содержит имя вызываемой функции, и т. д.).
Вывод
В этой статье были рассмотрены прошлые подходы к генерации сигнатур для вредоносных программ и предложен новый метод, основанный на глубоких сетях убеждений. Существующие подходы к генерации сигнатур вредоносных программ используют специфические аспекты вредоносного ПО (например, определенную нормальность сетевого трафика или подстроку в программе); таким образом, новые варианты вредоносного ПО легко уклоняются от обнаружения, изменяя небольшие части их кода.
Предложенный новый подход вдохновлен недавним успехом в обучении глубоких нейронных сетей, которые реализуют инвариантные представления. Сначала вредоносное ПО запускается в песочнице, а затем файл журнала песочница конвертируется в длинную двоичную битовую строку. Эта битовая строка подается в глубокую 8-слойную нейронную сеть, которая производит 30 значений в своем выходном уровне. Эти значения используются в качестве сигнатуры программы. Экспериментальные результаты показывают, что сигнатуры, созданные глубокими нейронными сетями, очень удобны для обнаружения вредоносных программ. Эти подписи могут либо использоваться в полностью неконтролируемой структуре, либо использоваться для контролируемой классификации вредоносных программ.
- Горбань А. Н. Обучение нейронных сетей. — М.: СССР-США-СП.: Параграф, 1990. — 160 с.
- Хайкин С. Нейронные сети: полный курс 2-е изд. — М.: Вильямс, 2006. — 1104 с.
- Ясницкий Л. Н. Введение в искусственный интеллект. — М.: Академия, 2005. — 176 с.
- Еремин Д. М., Гарцеев И. Б. Искусственные нейронные сети в интеллектуальных системах управления. — М.: МИРЭА, 2004. — 75 с.
- Терехов В. А., Ефимов Д. В., Тюкин И. Ю. Нейросетевые системы управления. — М.: Высшая школа, 2002. — 184 с.
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.
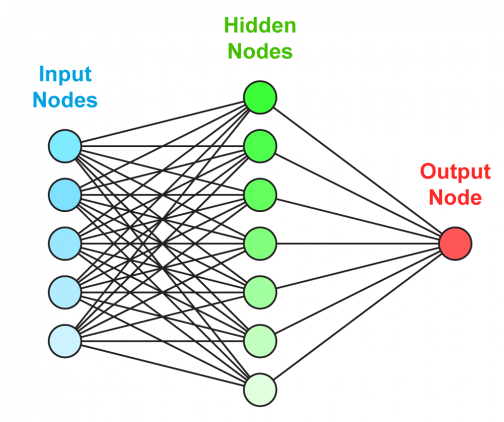
Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.
Обучение нейросетей происходит в два этапа:
- Прямое распространение ошибки;
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
Прямое распространение ошибки
Зададим начальные веса случайным образом:
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
Обратное распространение
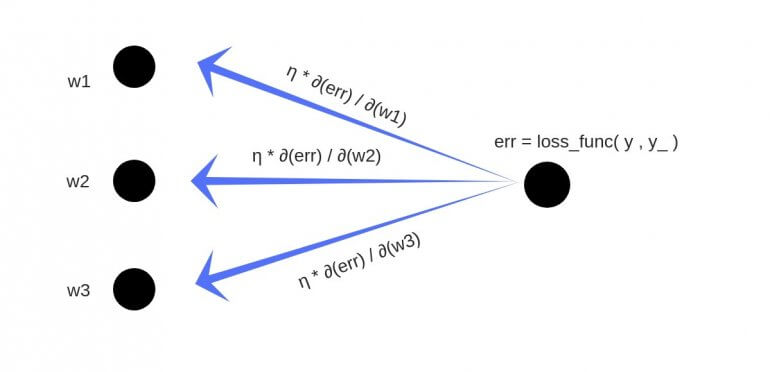
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.

Популярный мем о том, как Карлсон стал Data Science разработчиком
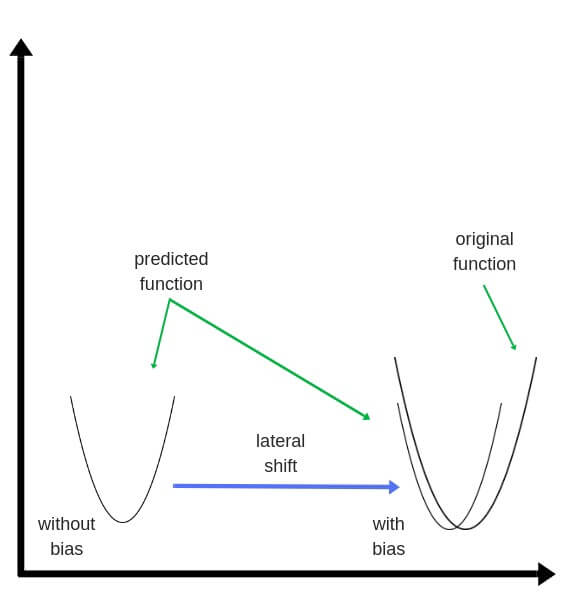
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
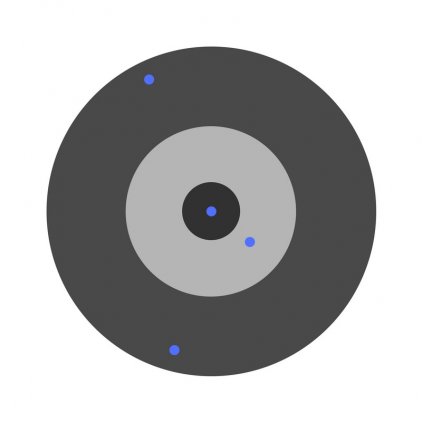
Разберем необходимость частных производных на примере.
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:
Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:
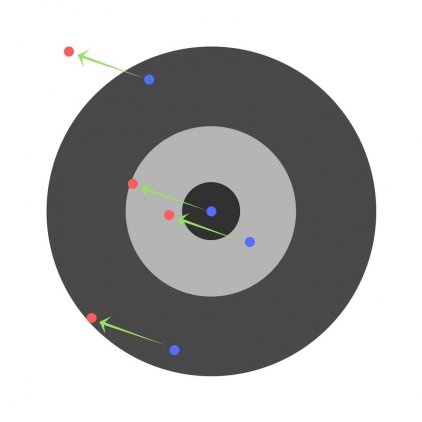
Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:
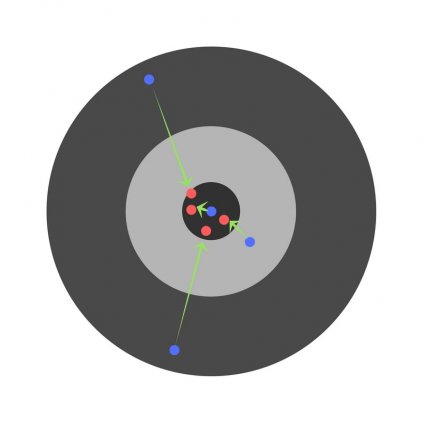
Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:
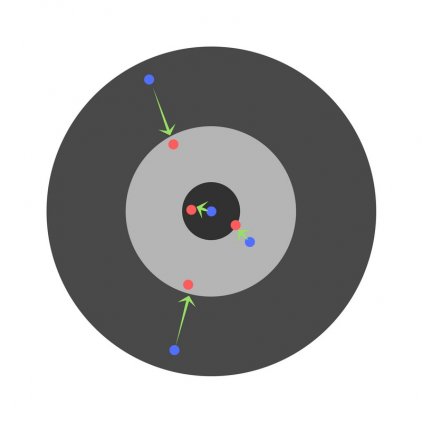
С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:
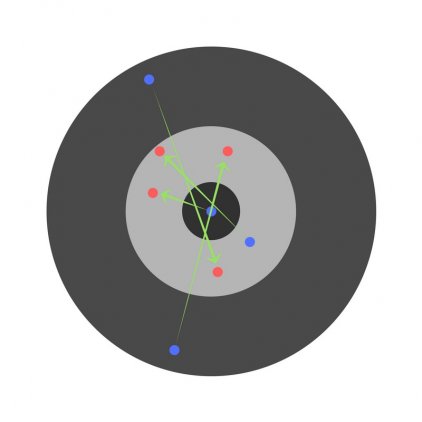
Функция активации (activation function)
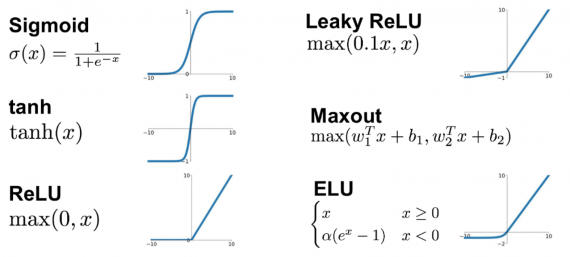
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:
Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака — Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:
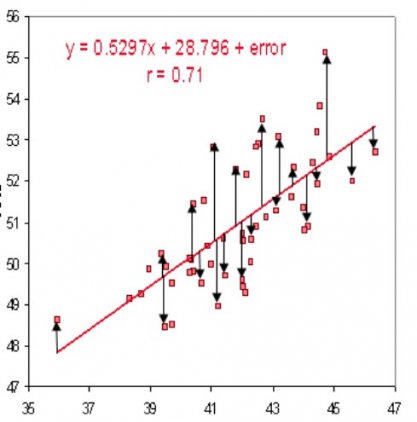
Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
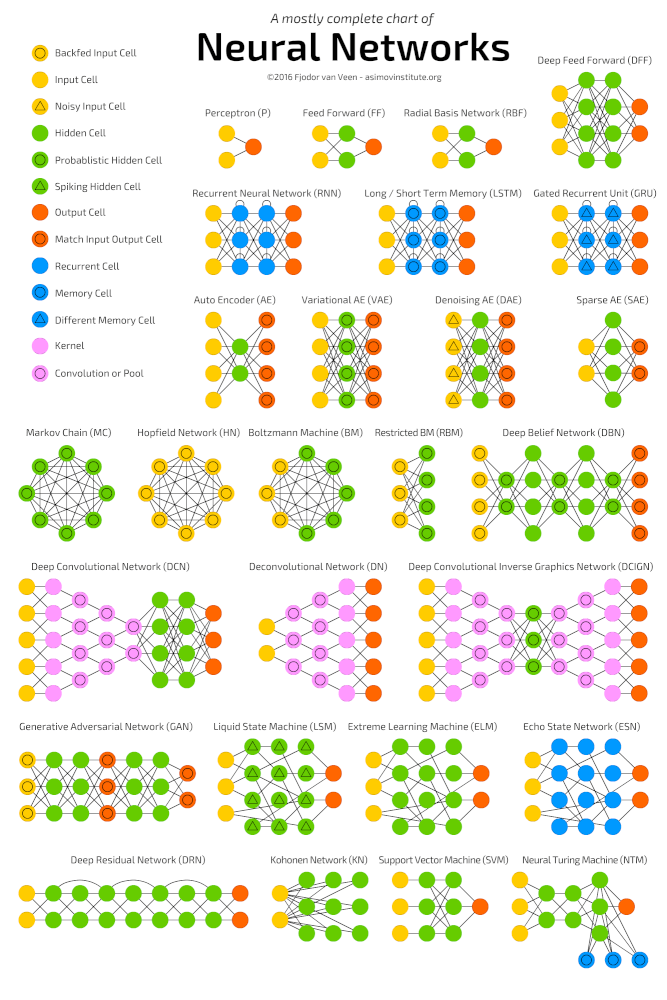
Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Рассмотрим однослойную нейронную сеть:
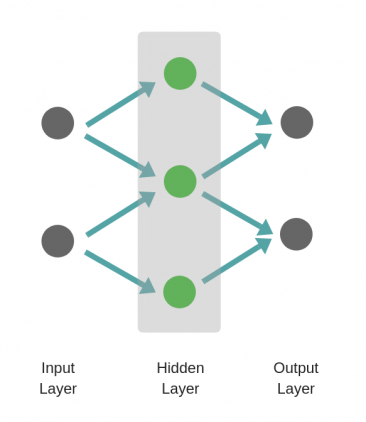
Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
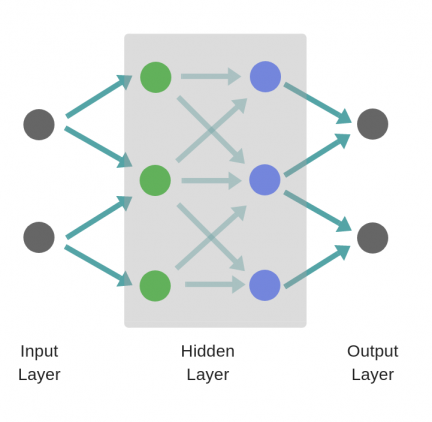
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:
Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.
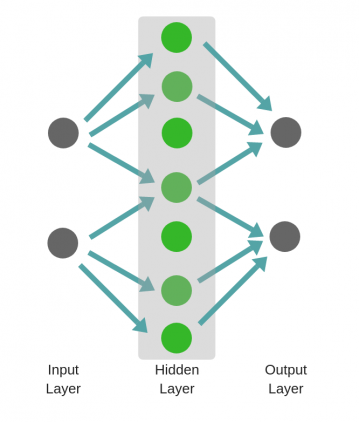
Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
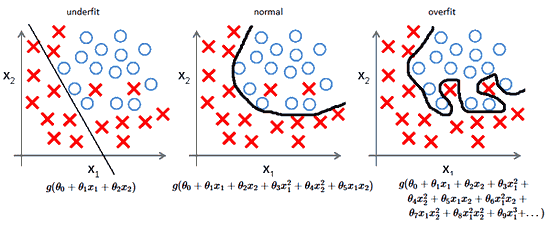
алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
Читайте также:
